A Context-Enriched NL-to-SQL Agent for Premier League Football Database Querying
Scaling Trustworthy NL-to-SQL for Complex Enterprise Domains
The Challenge: The "Living Document" Problem
Enterprise data in professional sports isn't just large; it’s governed by dense, legalistic corpora (handbooks and laws) that change annually. While Chain-of-Thought (CoT) prompting is the industry standard, it often fails when queries require domain-specific context not present in the model's weights.
The Methodology: A Comparative Architectural Study
I developed a 400-question benchmark of varying difficulty to test two distinct architectures against a representative subset of real-world football databases:
-
Intermediate Refinement Pipeline (RAG-R): A multi-model task that decomposes the process. It first "refines" the natural language query based on retrieved context before attempting SQL generation.
-
Direct Context Augmentation Agent (RAG-C): An end-to-end agentic workflow that uses context enrichment as a tool in a single execution loop.

Average Exact Set Match (EM) Accuracy: RAG-Refinement (62.7%) vs. Baseline Chain-of-Thought (51.1%)
Key Findings & Metrics
My analysis revealed that pipeline decomposition significantly outperforms agentic autonomy in high-precision tasks like NL-to-SQL.
-
Accuracy Boost: The RAG-Refinement approach improved average Exact Set Match (EM) accuracy from 51.1% to 62.7%.
-
Domain Specificity: For prompts whose meaning could not be derived without context, EM accuracy jumped from 24.4% to 52.2%—a 27.8% relative increase.
-
Baseline Comparison: The RAG-R architecture demonstrably outperformed ten-shot Chain-of-Thought, proving that structural context engineering beats raw prompting power.
Why This Matters for Enterprise AI
My analysis revealed that pipeline decomposition significantly outperforms agentic autonomy in high-precision tasks like NL-to-SQL.
-
Explainability: By using RAG over fine-tuning, administrators can retrieve the specific rules passage used to generate a query, ensuring a "glass box" rather than a "black box" approach.
-
Maintainability: In a "living document" domain, updating the system only requires re-embedding new corpora rather than expensive model re-training.
I am currently preparing the full findings of this research for publication. If you are interested in discussing the architectural trade-offs of RAG vs. Fine-tuning for your specific enterprise domain, I would love to connect.
.png)
The RAG-R Pipeline separates the Query Refinement step from the SQL Generation Step making the pipeline more auditable and reducing errors from context stuffing.
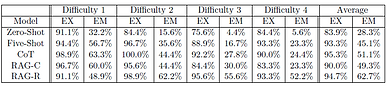
Note the performance delta at higher complexity (Difficulty 3 & 4). While standard Chain-of-Thought (CoT) accuracy degrades significantly as schemas grow more dense, the Intermediate Refinement (RAG-R) pipeline maintains high Exact Set Match (EM) accuracy by isolating the context enrichment and query-planning steps.